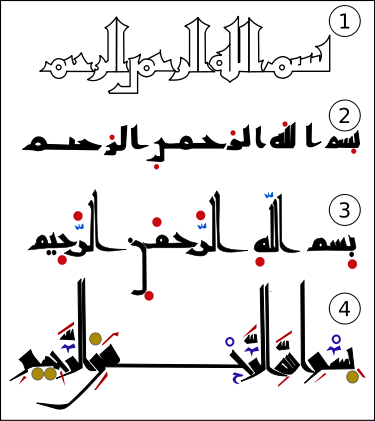
امروز به مطلبی در مورد پیدا کردن کلمههای با اهمیت در یک پیکره برخورد کردم که خیلی ساده دلیل استفاده از TF-IDF را توضیح داده بود. اینکه TF میتونه کمک کنه که واژههای مهم در سطح یک document را پیدا کنیم و IDF هم به ما نشون میده که از بین همه این کلمههای پرتکرار کدامیک مهمتر هستند.